
프론트엔드 아키텍처가 CSR에서 다시 SSR로 넘어오고 있고 RSC도 많이 언급이 되고 있습니다.
이런 흐름에 맞게 프론트엔드 개발자들에게도 서버와 인프라에 대한 지식도 점점 요구되고 있습니다.
이러한 흐름속에서 BFF에 대한 개념을 정리해보려고 합니다.
내가 알고 있던 BFF
제가 BFF에 대해서 이해하고 있던 내용은 아래와 같습니다.
- 클라이언트와 서버간의 통신에서 중간에 서버(BFF)를 하나 더 둔다.
- BFF는 프론트엔드에서의 요구사항을 충족시키기 위해 사용한다.
- 예를 들면, 프론트엔드에게 화면에 보여질 데이터만 전달하기 위해 사용한다.
- BFF의 관리는 팀의 구성에 따라서 다르다.
그런데 이 정도의 이해로는 언제 BFF를 사용하고 장점이 무엇인지 누군가를 설득시킬 수는 없는 내용이었습니다.
결국에 화면에 보여질 데이터만 정제하기 위해서 사용한다고 얘기하고 있는데 이러한 동작은 꼭 BFF라는 레이어를 하나 더 두지 않더라도 프론트엔드에서도 충분히 처리할 수 있는 동작이기 때문입니다.
BFF에서 API 서버로부터 response를 받았을 때, 해당 response를 정제하는 로직을 프론트단에 위치시키면 됩니다.
따라서, 기존에 제가 이해하던 내용으로는 BFF를 사용해야 하는 이유를 설명할수가 없었습니다.
왜냐하면 BFF와 함께 따라오는 MSA(Micro Service Architecture)라는 핵심 키워드가 빠져있었기 때문입니다.
MSA와 함께 따라오는 BFF
MSA란 도메인별로 독립적인 서비스로 나누고, 각각의 서비스들의 조합으로 개발하는 방식입니다.
기존의 모놀리틱 아키텍처에서는 하나의 서버에만 요청을 하고, 서버에서 디비를 거쳐 필요한 데이터를 가져오고 클라이언트에 전달하게 되지만 MSA에서는 필요한 데이터를 받아오기 위해서는 여러 가지 서비스들에게 요청을 보내고 응답을 받아와야 합니다. 따라서 클라이언트에서는 여러 개의 서비스에 요청을 보내고, 그 응답들을 조합하여 UI에 보여져야 할 테이터로 가공해야 하는 책임이 생기게 됩니다.
그리고 이 책임은 UI와 비즈니스 로직에 집중해야 하는 프론트엔드에서 복잡도를 높이게 됩니다.
물론 api레이어와 시리얼라이저(데이터를 가공하는)같은 레이어로 구분 지을 수도 있지만 프론트엔드에서 관리해야 하는 포인트가 많아지는 건 똑같다고 생각합니다. 그리고 서비스의 복잡도가 충분히 높은 상황이라면 레이어가 하나 생기는 것 만으로 부담일 수 있습니다.
그렇다면 MSA로 구성되어있는 환경에서 클라이언트는 어떻게 이런 복잡도를 해결할 수 있을까요?
결국에 책임을 분리하는 것입니다. 그리고 프론트엔드에서 데이터를 가공하는 책임을 분리하는 것이 BFF가 해결하는 문제입니다.
BFF는 MSA 환경에서 서비스와 프론트엔드 사이에 존재하여 클라이언트에 필요한 데이터를 가공하는 책임을 갖게 됩니다.
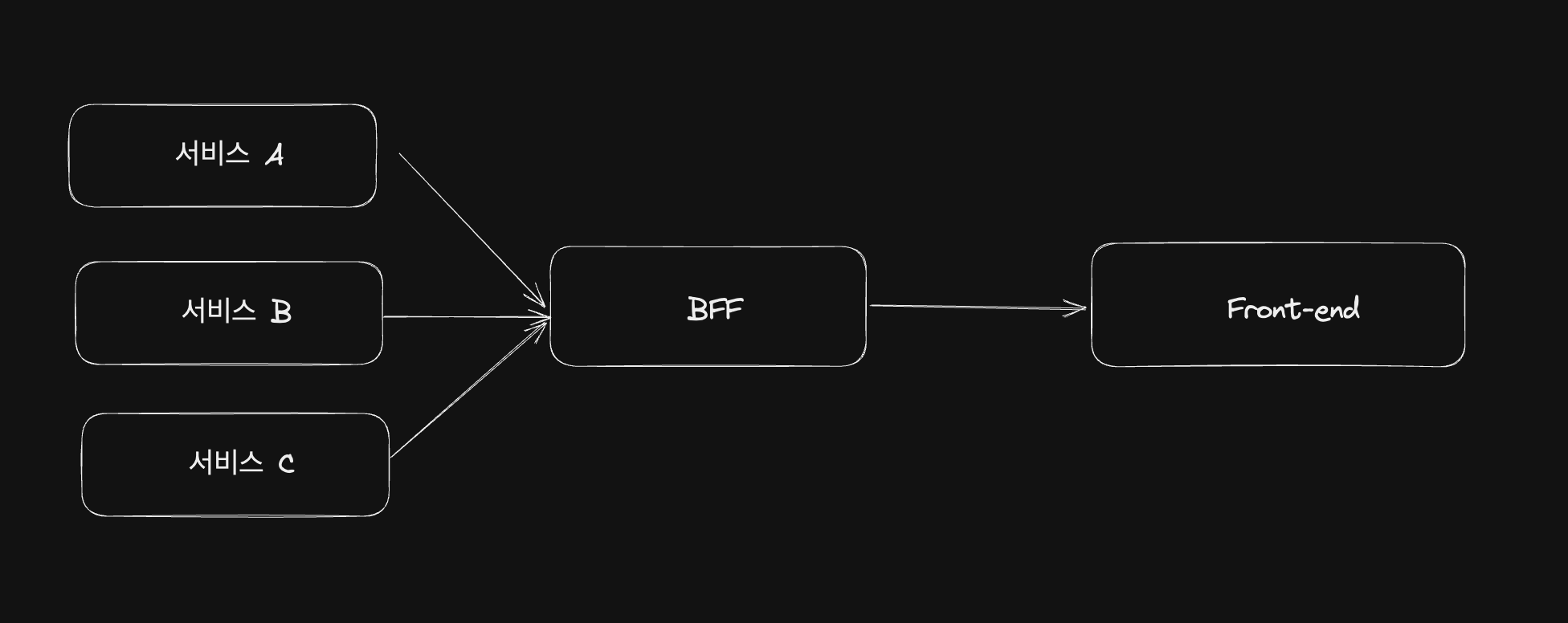
이렇게 되면 프론트엔드에서 데이터를 가공하는 책임은 BFF로 넘겨줄 수 있습니다.
프론트엔드로 부터 특정 데이터에 대한 요청이 들어왔을 때 BFF는 각 서비스들과 협력하여 데이터를 받아오고 가공하여 프론트엔드로 전달하게 됩니다. 프론트엔드 입장에서는 BFF 내부 구현이 어떻게 되어있는지는 모르고 BFF의 인터페이스에만 의존하고 있는데 이를 SOLID에서 Dependency Inversion Principle(의존성역전원칙)을 만족한다고 볼 수 있을 것 같습니다. 기존에는 각 서비스들과 직접 통신하여 데이터를 받아왔다면, 지금은 조금 더 고수준 모듈인 BFF에 의존하고 있기 때문입니다.
여기서 BFF는 여러개의 서비스에서 데이터를 받아와야 하기 때문에 처리량을 높이기 위해 비동기로 처리하면 좋습니다.
만약 클라이언트의 종류가 모바일이 추가된다고 하면 기존의 BFF로 3개의 클라이언트에 대한 요구사항을 모두 만족시켜야 합니다. 웹과 모바일에서 각각 보여지는 화면이 다르고 요구사항도 다른 경우가 있을 수 있습니다. 이는 하나의 서버에서 여러 개의 인터페이스를 충족시켜야 하는 것을 의미하고 처음에는 BFF를 이용하여 데이터를 가공하는 책임을 분리하여 복잡도를 낮췄지만 여러 개의 인터페이스를 다뤄야 하는 책임이 생겼고 이는 BFF 자체의 복잡도가 높아지는 문제가 발생하게 됩니다.
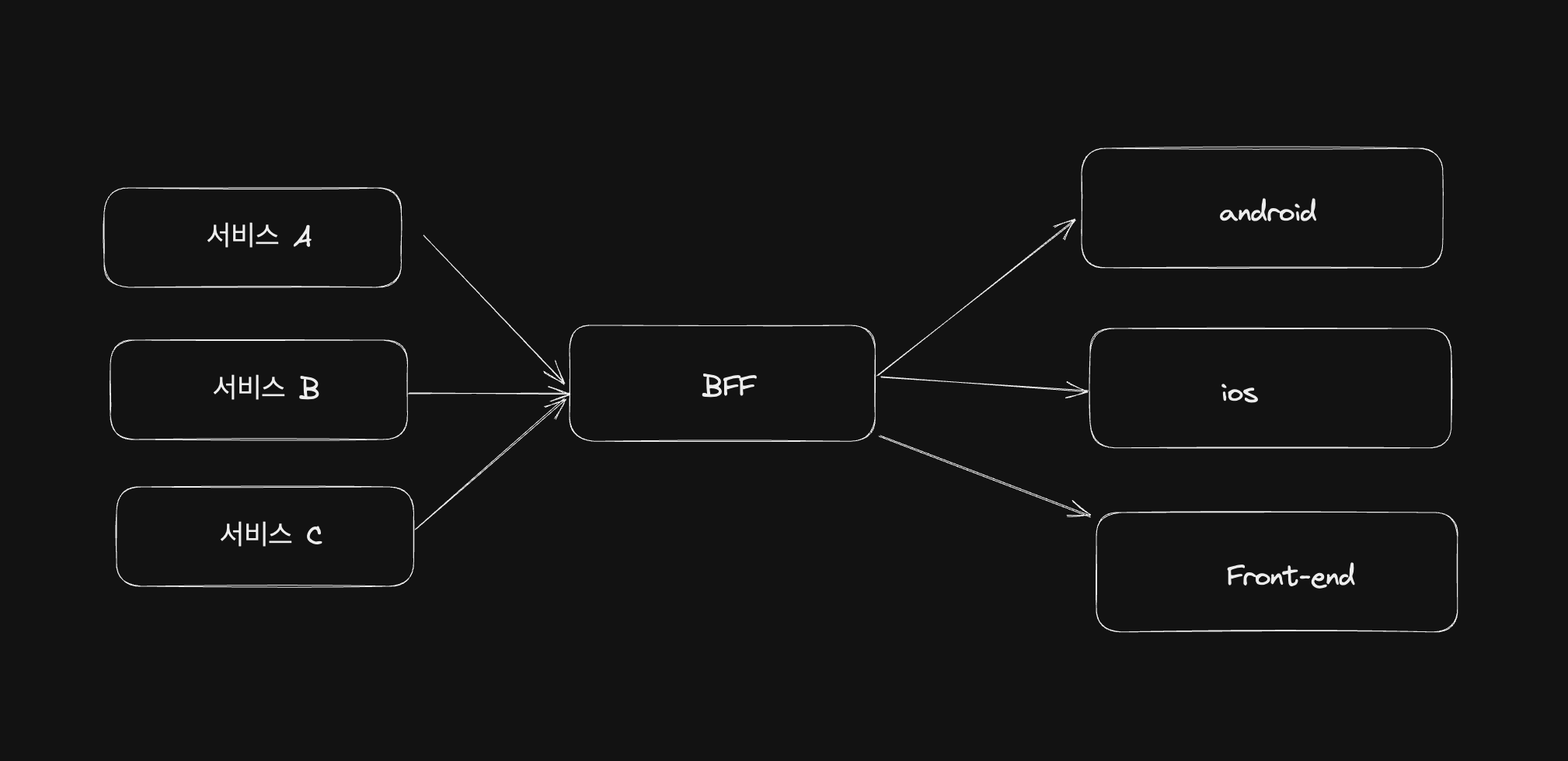
이를 해결하기 위해서는 BFF 또한 클라이언트에 1:1 대응이 되도록 구성해줄 수 있습니다.
이렇게 되면 하나의 BFF가 만족시켜야 했던 여러개의 인터페이스를 클라이언트에 대응되는 각각의 BFF에서 다루게 됨으로써 책임을 한번 더 분리할 수 있습니다.
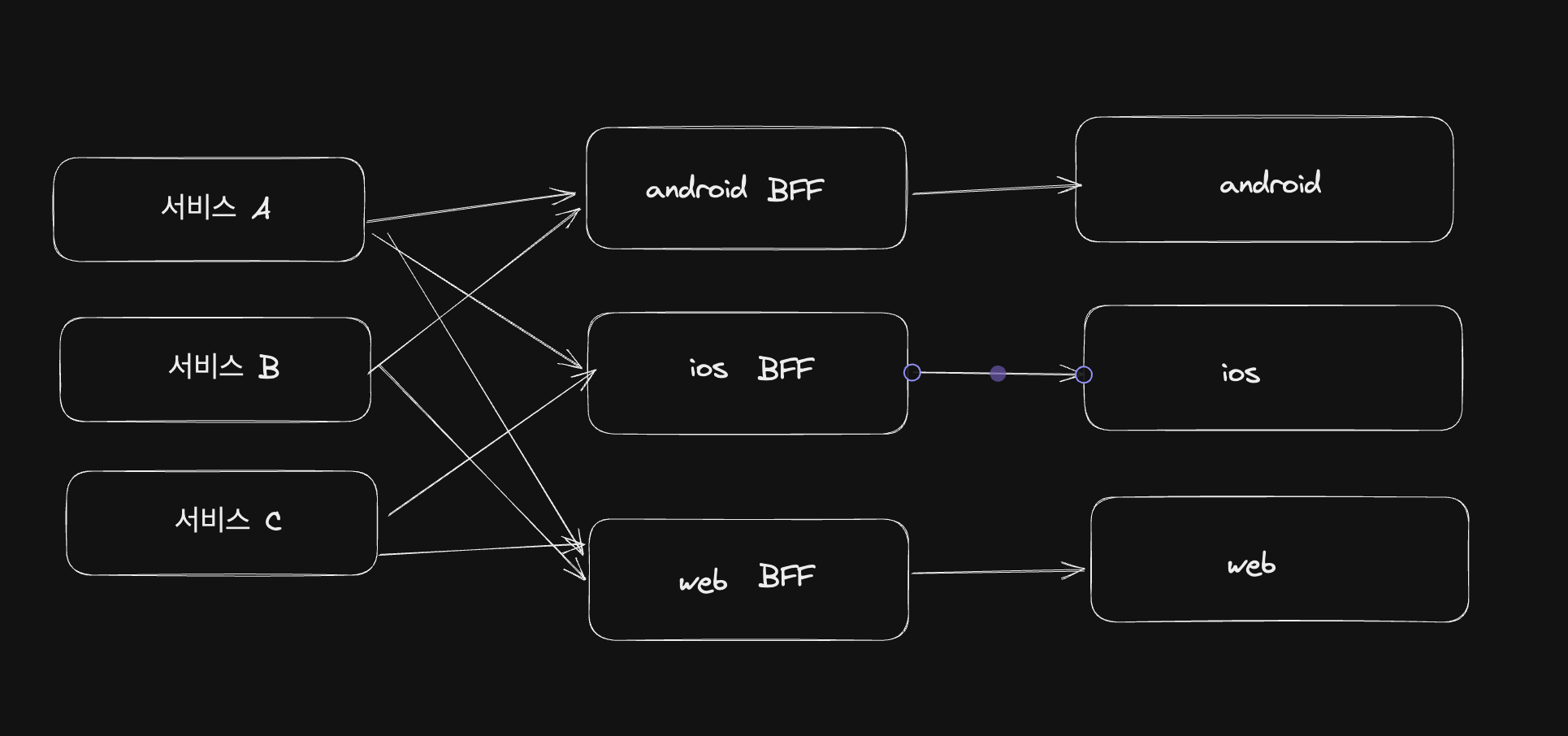
만약 요구사항이나 화면이 크게 다르지 않고 필요한 데이터가 약간 다른 정도라면 BFF를 RestAPI가 아닌 GraphQL로 구축하는 것도 좋은 방안이 될 수 있습니다. 클라이언트에서 원하는 데이터를 선언적으로 표현하여 BFF에 전달해 주면, BFF에서 클라이언트에서 원하는 데이터만 응답해 줄 수 있기 때문입니다.
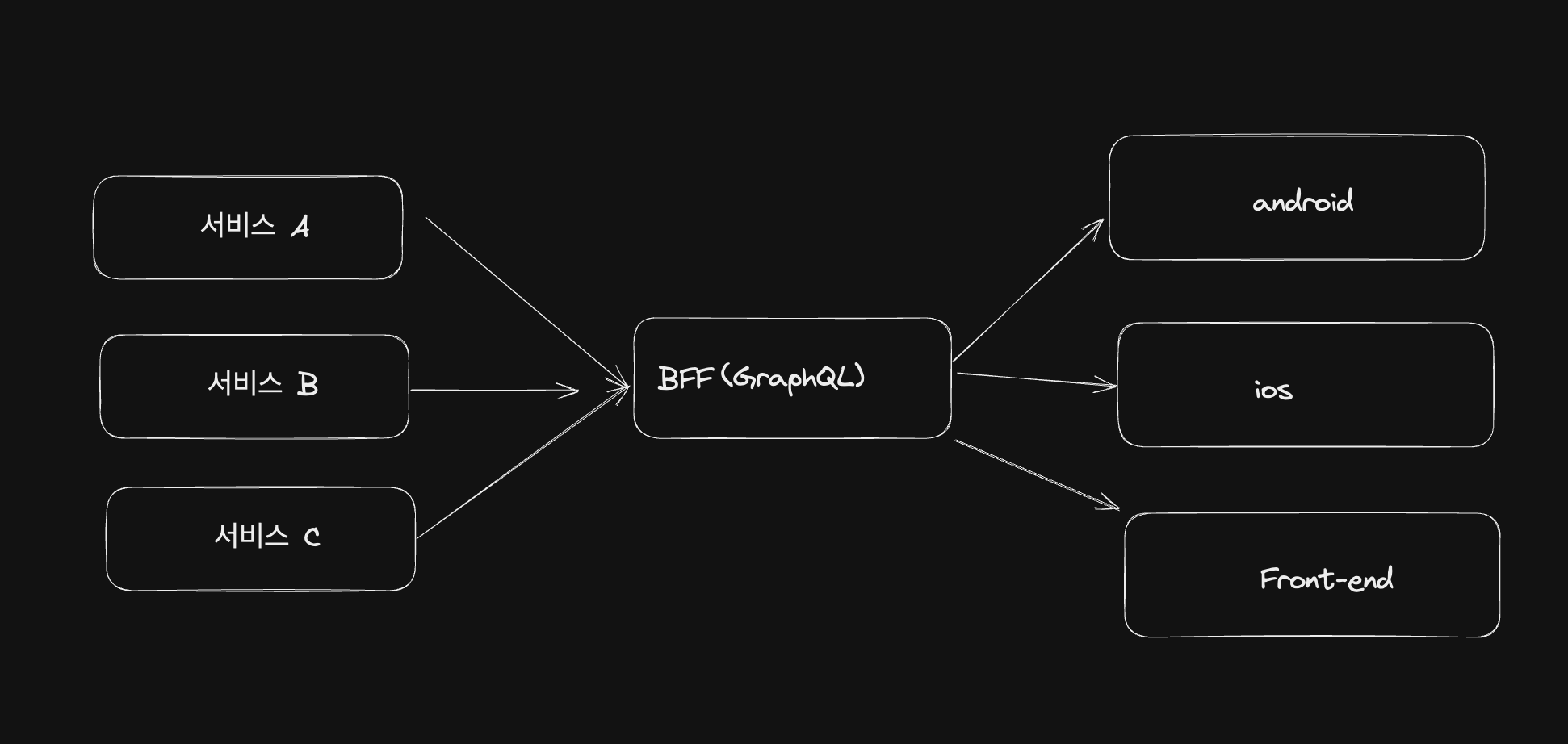
이렇게 BFF가 해결하는 문제를 살펴볼 수 있었습니다.
BFF에서는 데이터를 가공하는 것 이외에 클라이언트에 전달하면 문제가 생길 수 있는 중요한 정보들을 숨기거나 에러처리를 일관되게 하는 등의 책임도 포함시켜 줄 수 있습니다.
정리
- BFF는 프론트엔드가 바라보는 서버가 1개라면 필요가 없다.
- BFF는 MSA 환경에서 다양한 서비스들의 데이터를 가공하여 클라이언트에게 전달하는 책임을 갖는다.
- 프론트엔드에서 데이터를 가공하는 책임을 BFF로 분리함으로써 핵심이 되는 비즈니스 로직에 집중할 수 있다.
- BFF에는 오직 클라이언트에 특정된 로직만 담겨있어야 한다.
- BFF로 인한 기술 부채가 발생하면 안 된다.
출처
https://fe-developers.kakaoent.com/2022/220310-kakaopage-bff/
https://tech.kakaopay.com/post/bff_webflux_coroutine/
https://learn.microsoft.com/en-us/azure/architecture/patterns/backends-for-frontends
https://fe-developers.kakaoent.com/2023/230925-bff-trouble-shooting/
'TIL > 개발' 카테고리의 다른 글
| 요즘 개발자 베타리딩 - 2주차 (0) | 2023.11.09 |
|---|---|
| 프론트엔드에서의 비즈니스 로직은 어떻게 분리할 수 있을까요? (0) | 2023.11.09 |
| React에서 useCallback은 언제 사용해야 할까? (0) | 2023.11.08 |
| [Astro] Astro 3.0에서 달라진 것들 (0) | 2023.09.01 |
| 테스트코드와 SPA 환경을 만들어보며 배우는 모던 자바스크립트 입문 - 1주차 (0) | 2023.04.03 |
프론트엔드 아키텍처가 CSR에서 다시 SSR로 넘어오고 있고 RSC도 많이 언급이 되고 있습니다.
이런 흐름에 맞게 프론트엔드 개발자들에게도 서버와 인프라에 대한 지식도 점점 요구되고 있습니다.
이러한 흐름속에서 BFF에 대한 개념을 정리해보려고 합니다.
내가 알고 있던 BFF
제가 BFF에 대해서 이해하고 있던 내용은 아래와 같습니다.
- 클라이언트와 서버간의 통신에서 중간에 서버(BFF)를 하나 더 둔다.
- BFF는 프론트엔드에서의 요구사항을 충족시키기 위해 사용한다.
- 예를 들면, 프론트엔드에게 화면에 보여질 데이터만 전달하기 위해 사용한다.
- BFF의 관리는 팀의 구성에 따라서 다르다.
그런데 이 정도의 이해로는 언제 BFF를 사용하고 장점이 무엇인지 누군가를 설득시킬 수는 없는 내용이었습니다.
결국에 화면에 보여질 데이터만 정제하기 위해서 사용한다고 얘기하고 있는데 이러한 동작은 꼭 BFF라는 레이어를 하나 더 두지 않더라도 프론트엔드에서도 충분히 처리할 수 있는 동작이기 때문입니다.
BFF에서 API 서버로부터 response를 받았을 때, 해당 response를 정제하는 로직을 프론트단에 위치시키면 됩니다.
따라서, 기존에 제가 이해하던 내용으로는 BFF를 사용해야 하는 이유를 설명할수가 없었습니다.
왜냐하면 BFF와 함께 따라오는 MSA(Micro Service Architecture)라는 핵심 키워드가 빠져있었기 때문입니다.
MSA와 함께 따라오는 BFF
MSA란 도메인별로 독립적인 서비스로 나누고, 각각의 서비스들의 조합으로 개발하는 방식입니다.
기존의 모놀리틱 아키텍처에서는 하나의 서버에만 요청을 하고, 서버에서 디비를 거쳐 필요한 데이터를 가져오고 클라이언트에 전달하게 되지만 MSA에서는 필요한 데이터를 받아오기 위해서는 여러 가지 서비스들에게 요청을 보내고 응답을 받아와야 합니다. 따라서 클라이언트에서는 여러 개의 서비스에 요청을 보내고, 그 응답들을 조합하여 UI에 보여져야 할 테이터로 가공해야 하는 책임이 생기게 됩니다.
그리고 이 책임은 UI와 비즈니스 로직에 집중해야 하는 프론트엔드에서 복잡도를 높이게 됩니다.
물론 api레이어와 시리얼라이저(데이터를 가공하는)같은 레이어로 구분 지을 수도 있지만 프론트엔드에서 관리해야 하는 포인트가 많아지는 건 똑같다고 생각합니다. 그리고 서비스의 복잡도가 충분히 높은 상황이라면 레이어가 하나 생기는 것 만으로 부담일 수 있습니다.
그렇다면 MSA로 구성되어있는 환경에서 클라이언트는 어떻게 이런 복잡도를 해결할 수 있을까요?
결국에 책임을 분리하는 것입니다. 그리고 프론트엔드에서 데이터를 가공하는 책임을 분리하는 것이 BFF가 해결하는 문제입니다.
BFF는 MSA 환경에서 서비스와 프론트엔드 사이에 존재하여 클라이언트에 필요한 데이터를 가공하는 책임을 갖게 됩니다.
이렇게 되면 프론트엔드에서 데이터를 가공하는 책임은 BFF로 넘겨줄 수 있습니다.
프론트엔드로 부터 특정 데이터에 대한 요청이 들어왔을 때 BFF는 각 서비스들과 협력하여 데이터를 받아오고 가공하여 프론트엔드로 전달하게 됩니다. 프론트엔드 입장에서는 BFF 내부 구현이 어떻게 되어있는지는 모르고 BFF의 인터페이스에만 의존하고 있는데 이를 SOLID에서 Dependency Inversion Principle(의존성역전원칙)을 만족한다고 볼 수 있을 것 같습니다. 기존에는 각 서비스들과 직접 통신하여 데이터를 받아왔다면, 지금은 조금 더 고수준 모듈인 BFF에 의존하고 있기 때문입니다.
여기서 BFF는 여러개의 서비스에서 데이터를 받아와야 하기 때문에 처리량을 높이기 위해 비동기로 처리하면 좋습니다.
만약 클라이언트의 종류가 모바일이 추가된다고 하면 기존의 BFF로 3개의 클라이언트에 대한 요구사항을 모두 만족시켜야 합니다. 웹과 모바일에서 각각 보여지는 화면이 다르고 요구사항도 다른 경우가 있을 수 있습니다. 이는 하나의 서버에서 여러 개의 인터페이스를 충족시켜야 하는 것을 의미하고 처음에는 BFF를 이용하여 데이터를 가공하는 책임을 분리하여 복잡도를 낮췄지만 여러 개의 인터페이스를 다뤄야 하는 책임이 생겼고 이는 BFF 자체의 복잡도가 높아지는 문제가 발생하게 됩니다.
이를 해결하기 위해서는 BFF 또한 클라이언트에 1:1 대응이 되도록 구성해줄 수 있습니다.
이렇게 되면 하나의 BFF가 만족시켜야 했던 여러개의 인터페이스를 클라이언트에 대응되는 각각의 BFF에서 다루게 됨으로써 책임을 한번 더 분리할 수 있습니다.
만약 요구사항이나 화면이 크게 다르지 않고 필요한 데이터가 약간 다른 정도라면 BFF를 RestAPI가 아닌 GraphQL로 구축하는 것도 좋은 방안이 될 수 있습니다. 클라이언트에서 원하는 데이터를 선언적으로 표현하여 BFF에 전달해 주면, BFF에서 클라이언트에서 원하는 데이터만 응답해 줄 수 있기 때문입니다.
이렇게 BFF가 해결하는 문제를 살펴볼 수 있었습니다.
BFF에서는 데이터를 가공하는 것 이외에 클라이언트에 전달하면 문제가 생길 수 있는 중요한 정보들을 숨기거나 에러처리를 일관되게 하는 등의 책임도 포함시켜 줄 수 있습니다.
정리
- BFF는 프론트엔드가 바라보는 서버가 1개라면 필요가 없다.
- BFF는 MSA 환경에서 다양한 서비스들의 데이터를 가공하여 클라이언트에게 전달하는 책임을 갖는다.
- 프론트엔드에서 데이터를 가공하는 책임을 BFF로 분리함으로써 핵심이 되는 비즈니스 로직에 집중할 수 있다.
- BFF에는 오직 클라이언트에 특정된 로직만 담겨있어야 한다.
- BFF로 인한 기술 부채가 발생하면 안 된다.
출처
https://fe-developers.kakaoent.com/2022/220310-kakaopage-bff/
https://tech.kakaopay.com/post/bff_webflux_coroutine/
https://learn.microsoft.com/en-us/azure/architecture/patterns/backends-for-frontends
https://fe-developers.kakaoent.com/2023/230925-bff-trouble-shooting/
'TIL > 개발' 카테고리의 다른 글
| 요즘 개발자 베타리딩 - 2주차 (0) | 2023.11.09 |
|---|---|
| 프론트엔드에서의 비즈니스 로직은 어떻게 분리할 수 있을까요? (0) | 2023.11.09 |
| React에서 useCallback은 언제 사용해야 할까? (0) | 2023.11.08 |
| [Astro] Astro 3.0에서 달라진 것들 (0) | 2023.09.01 |
| 테스트코드와 SPA 환경을 만들어보며 배우는 모던 자바스크립트 입문 - 1주차 (0) | 2023.04.03 |